Apache Spark
Tematyka zajęć:
- Analiza logu serwera WWW (cd. lab.02)
- Analiza ruchu lotniczego
- Spark z linii polecenia

Tematyka zajęć:
import findspark findspark.init()
# configure spark variables from pyspark.context import SparkContext from pyspark.sql.context import SQLContext from pyspark.sql.session import SparkSession sc = SparkContext() sqlContext = SQLContext(sc) spark = SparkSession(sc) # load up other dependencies import re import pandas as pd
m = re.finditer(r'.*?(spark).*?', "I'm searching for a spark in PySpark", re.I)
for match in m:
print(match, match.start(), match.end())
raw_data_files = ['/home/spark/files/access_log1', '/home/spark/files/access_log2'] base_df = spark.read.text(raw_data_files) base_df.printSchema()
type(base_df)
base_df.show(5, truncate=False)
base_df_rdd = base_df.rdd
type(base_df_rdd)
base_df_rdd.take(5)
from pyspark.sql.functions import regexp_extract
log_df = base_df.select(regexp_extract('value', r'(^[\S+]+) -', 1).alias('host'),
regexp_extract('value', r'(^[\S+]+) - - \[(.*)\]', 2).alias('timestamp'),
regexp_extract('value', r'(^[\S+]+) - - \[(.*)\] "(\w+)', 3).alias('method'),
regexp_extract('value', r'(^[\S+]+) - - \[(.*)\] "(\w+) (.*?) (.*?)', 4).alias('endpoint'),
regexp_extract('value', r'(^[\S+]+) - - \[(.*) \+(.*)\] "(\w+) (.*?) (.*?)" ', 6).alias('protocol'),
regexp_extract('value', r'(^[\S+]+) - - \[(.*) \+(.*)\] "(\w+) (.*?) (.*?)" (\d+) ', 7).cast('integer').alias('status'),
regexp_extract('value', r'(^[\S+]+) - - \[(.*) \+(.*)\] "(\w+) (.*?) (.*?)" (\d+) (\d+)', 8).cast('integer').alias('content_size'))
log_df.show(10, truncate=True)
print((log_df.count(), len(log_df.columns)))
(log_df
.filter(log_df['content_size']
.isNull())
.count())
bad_rows_df = log_df.filter(log_df['host'].isNull()|
log_df['timestamp'].isNull() |
log_df['method'].isNull() |
log_df['endpoint'].isNull() |
log_df['status'].isNull() |
log_df['content_size'].isNull()|
log_df['protocol'].isNull())
bad_rows_df.count()
bad_rows_df.show(5)
log_df = log_df.na.fill({'content_size': 0})
log_df.count()
log_df1 = log_df[~log_df['timestamp'].isin([''])] log_df1.count()
from pyspark.sql.functions import udf
month_map = {
'Jan': 1, 'Feb': 2, 'Mar':3, 'Apr':4, 'May':5, 'Jun':6, 'Jul':7,
'Aug':8, 'Sep': 9, 'Oct':10, 'Nov': 11, 'Dec': 12
}
def parse_clf_time(text):
""" Convert Common Log time format into a Python datetime object
Args:
text (str): date and time in Apache time format [dd/mmm/yyyy:hh:mm:ss (+/-)zzzz]
Returns:
a string suitable for passing to CAST('timestamp')
"""
# NOTE: We're ignoring the time zones here, might need to be handled depending on the problem you are solving
return "{0:04d}-{1:02d}-{2:02d} {3:02d}:{4:02d}:{5:02d}".format(
int(text[7:11]),
month_map[text[3:6]],
int(text[0:2]),
int(text[12:14]),
int(text[15:17]),
int(text[18:20])
)
udf_parse_time = udf(parse_clf_time)
log_dfn = (log_df1.select('*', udf_parse_time(log_df1['timestamp'])
.cast('timestamp')
.alias('time'))
.drop('timestamp'))
log_dfn.printSchema()
log_dfn.createOrReplaceTempView("logs")
import matplotlib.pyplot as plt import seaborn as sns import numpy as np %matplotlib inline
def bar_plot_list_of_tuples_horizontal(input_list,x_label,y_label,plot_title):
y_labels = [val[0] for val in input_list]
x_labels = [val[1] for val in input_list]
plt.figure(figsize=(12, 6))
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.title(plot_title)
ax = pd.Series(x_labels).plot(kind='barh')
ax.set_yticklabels(y_labels)
for i, v in enumerate(x_labels):
ax.text(int(v) + 0.5, i - 0.25, str(v),ha='center', va='bottom')
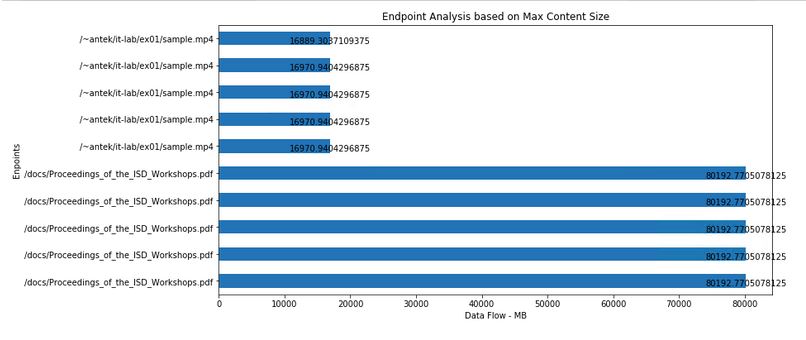
topEndpointsMaxSize = (sqlContext
.sql("SELECT endpoint,content_size/1024 FROM logs ORDER BY content_size DESC LIMIT 10")
.rdd.map(lambda row: (row[0], row[1]))
.collect())
bar_plot_list_of_tuples_horizontal(topEndpointsMaxSize,'Data Flow - MB','Enpoints','Endpoint Analysis based on Max Content Size')
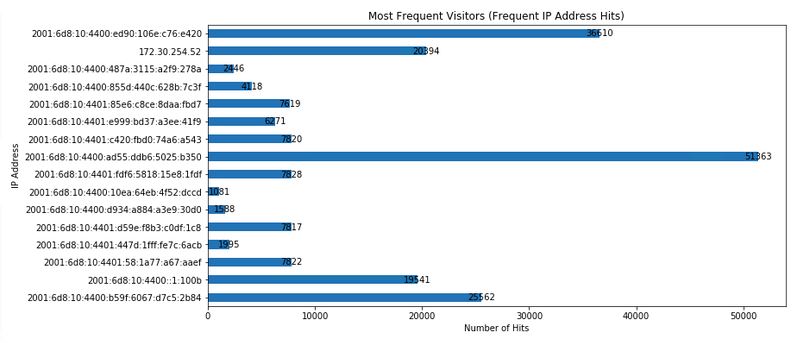
frequentIpAddressesHits = (sqlContext
.sql("SELECT host, COUNT(*) AS total FROM logs GROUP BY host HAVING total > 1000")
.rdd.map(lambda row: (row[0], row[1]))
.collect())
bar_plot_list_of_tuples_horizontal(frequentIpAddressesHits,'Number of Hits','IP Address','Most Frequent Visitors (Frequent IP Address Hits)')
import pyspark.sql.functions as F
host_day_df = log_dfn.select(log_dfn.host,
F.dayofmonth('time').alias('day'))
status_freq_df = (log_dfn
.groupBy('status')
.count()
.sort('status')
.cache())
print('Total distinct HTTP Status Codes:', status_freq_df.count())
log_freq_df = status_freq_df.withColumn('log(count)',
F.log(status_freq_df['count']))
log_freq_df.show()
host_day_df.show(5, truncate=False)
def_mr = pd.get_option('max_rows')
pd.set_option('max_rows', 10)
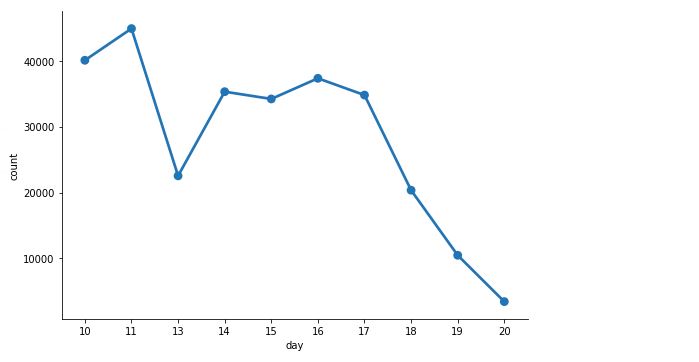
daily_hosts_df = (host_day_df
.groupBy('day')
.count()
.sort("day"))
daily_hosts_df.show(10, truncate=True)
daily_hosts_pd_df = (daily_hosts_df
.toPandas()
.sort_values(by=['count'],
ascending=False))
c = sns.catplot(x='day', y='count',
data=daily_hosts_pd_df,
kind='point', height=5,
aspect=1.5)
import findspark findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark Data Exploration") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
#import libraries
import pandas as pd
import matplotlib.pyplot as plt
import random
%matplotlib inline
#set ggplot style
plt.style.use('ggplot')
df = spark.read.format('com.databricks.spark.csv').\
options(header='true', \
inferschema='true').load("/home/spark/files/2008.csv",header=True);
df.columns
Opis kolumn w zbiorze danych:
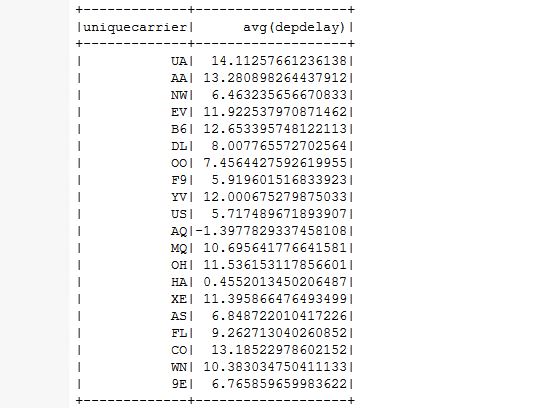
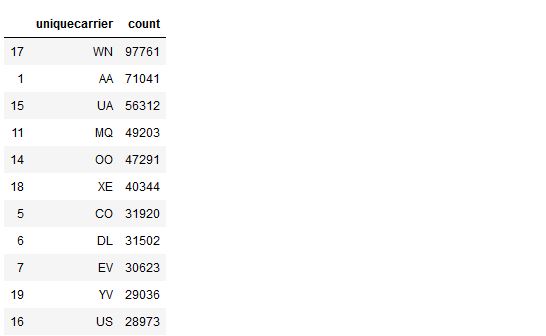
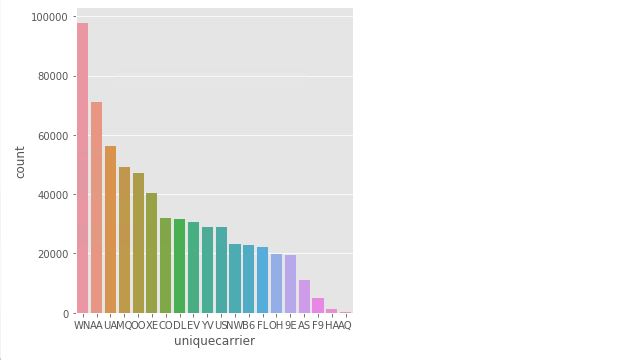
df.groupBy("UniqueCarrier").count().show()

df.cache
df.createOrReplaceTempView("flights")
spark.catalog.cacheTable("flights")
import matplotlib.pyplot as plt import seaborn as sns import numpy as np %matplotlib inline
import pyspark.sql.functions as F
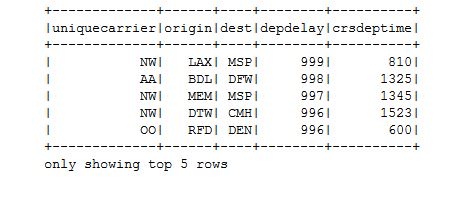
crshour = df.select('DepDelay', F.round(F.col('CRSDepTime')/100).cast('integer').alias('CRSDepHour'))
crshour.show()
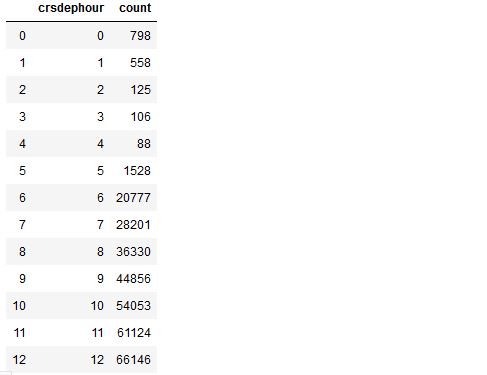
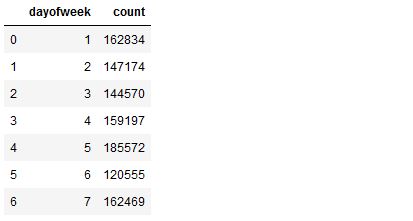
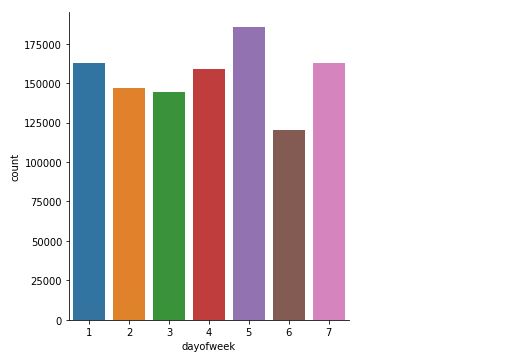
crshour_count = ( crshour.filter(df.DepDelay > 20).groupBy('crsdephour').count().sort('crsdephour').cache())
crshour_count_pd = ( crshour_count.toPandas().sort_values(by=['crsdephour']))
crshour_count_pd
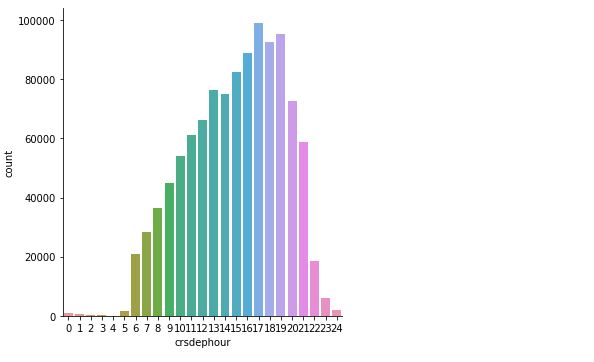
sns.catplot(x='crsdephour', y='count', data=crshour_count_pd,kind='bar',order=crshour_count_pd['crsdephour'] )
export SPARK_HOME=/usr/local/spark/ export PATH=$SPARK_HOME/bin:$PATH export PYSPARK_PYTHON=python3
spark-shell
pyspark
from pyspark import SparkConf, SparkFiles
from pyspark.sql import SparkSession
import time
import os
import sys
conf = SparkConf().setAppName("test")
spark = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
print("============")
with open("/home/spark/example/data.csv", 'r') as fh:
print(fh.read())
#time.sleep(300)
spark.stop()
spark-submit --master local[3] read.py
mkdir conf cp $SPARK_HOME/conf/log4j.properties.template conf/log4j.properties
spark-submit --master local[3] \
--driver-java-options "-Dlog4j.configuration=file:/home/anton/conf/log4j.properties" \
--conf "spark.executor.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties" \
--files "/home/anton/conf/log4j.properties" \
main.py